



开始
1、有人说,ChatGPT是个文科生。
这么说,只因为ChatGPT是一种大型语言模型,基于自然语言处理技术,通过深度学习模型对大量文本数据进行训练,从而学习到语言的规律和语义表达。
2、有人说,ChatGPT是个理科生。
自然语言处理本质上仍然是计算机语言。其发展的第二阶段是基于统计的机器学习,第三阶段是基于神经网络的深度学习,和人类的语言学规则关系不大。
3、还有人说,ChatGPT是个体育生。
创造了阿尔法狗的哈萨比斯认为,ChatGPT仅仅是更多的计算能力和数据的蛮力,并对这种“不优雅”的方式感到失望。
本文将从一道经典的“两孩难题”开始,引出ChatGPT背后的概率思维,以及19世纪以来人类面临的不确定性困境。
自亚里士多德与柏拉图之间的辩论开始,到休谟和贝叶斯二人隔着历史的相杀相爱,再到不愿意相信上帝是在扔骰子的因果哲学坚守者爱因斯坦,人类在哲学和科学范畴里纠结于确定性与不确定性,并且越陷越深。
我偏向于用一种介于“乐观”和“怀疑”之间的态度来评判ChatGPT引发的又一轮AI热潮。
本文将用一种个人化的方式,从零基础数学计算的源头,再推演一遍贝叶斯公式,和概率推理的机制,以及神经网络的基本原理。
进而,经过了简单但却可感知的数学计算,我们就可以顺着休谟的经验主义和怀疑论,一路奔袭到罗素的逻辑原子主义,直至维特根斯坦的立场:
语言的界限,就是世界的界限。
人工智能的变迁,几乎对应着人类认知世界的变迁结构。
从确定性到不确定性,从物理定律到统计概率,物理和信息交汇于“熵”,并以类似的达尔文观念,进化出有生命的熵减系统。
在这个愈发茫然的世界里,AI在疫情后时代获得了世人额外的关切;
诸神已被人类背弃,算法用强大而未知的相关性替代了神秘主义和因果霸权,仿佛成为新神。
真实与信念,确定与随机,意识与虚无,再次于大众的狂欢之中,对峙在时代的断崖边缘。
一
我们来看99%的聪明人都搞错了的问题。
问题:一个家庭里有两个孩子,其中一个是男孩,假设每个孩子是男孩女孩的概率一样,那么另一个孩子也是男孩的概率是多少?
直觉上,生男生女绝大多数时候是独立事件,其中一个是男孩,并不会影响另外一个孩子性别的概率,所以答案难道不是50%吗?
有些顶尖聪明人说:不对。正确的答案应该是1/3。
用古典概率的计算方法如下:
两个孩子的性别共有4种情况:
(男,男)、(女,女)、(男,女)、(女,男)
请注意,上述第三种和第四种情况,特别强调了老大和老二的区别。
如上四种情况中,其中一个是男孩共有3种情况:
(男,男)、(男,女)、(女,男)
另一个也是男孩只有1种情况:(男,男),所以概率是1/3。
麻烦来了:这是不是说,一个家庭假如有了一个男孩,再生一个男孩的概率就变成1/3了?
这不科学啊。
聪明如你,应当能从这看似严谨但其实含混的表述中发现秘密:
上面的计算,考虑了“有一个男孩家庭”里男孩是老大或老二的两种可能,但是却忽略了问题里“一个男孩”在“两个孩子都是男孩的家庭”里也有老大和老二两种可能。
所以,仅就本文开头题目的表述而言,答案仍然应该是1/2。
二
让我们在这个经典的“两孩难题”上再前进一步。
坚持认为正确答案是1/3的聪明人,会拿出贝叶斯公式。
他们认为,本文开头的题目,不是古典概率问题,而是条件概率问题。
所谓“条件概率”,是指:事件A在另外一个事件B已经发生条件下的发生概率。
条件概率表示为:P(A|B),读作“在B条件下A的概率”。
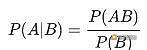
根据该公式,计算如下:
条件B:两个孩子其中一个是男孩。
考虑其对立事件:两个孩子都不是男孩,或者说两个孩子都是女孩。
P(B)=1-(1/2)×(1/2)=1-1/4=3/4
事件A:另一个也是男孩。
事件A、B同时发生:两个孩子都是男孩
P(AB)=(1/2)×(1/2)=1/4
P(A|B)=P(AB)/P(B)=(1/4)/(3/4)=1/3
所以,P(A|B)=1/3。
慢着,这是语言游戏吗?
答案到底是1/2,还是1/3?
难道贝叶斯公式也错了吗?
这一节的计算是“对”的,但根据该计算得出的结论应该是:
你观察到的这个男孩,来自两孩家庭的概率是1/3。
我不止一次地看到,即使是很聪明的人,以及专业人士,都在如上这一问题上绕不出来。
为什么呢?
因为语言的世界,不同语言的世界,个体观察的世界,不同个体观察的世界,以及上帝视野的世界,和所谓“真实“的世界,似乎都不是同一个世界。
三
在微软的报告里,研究者用GPT-4模拟了一段对话:
苏格拉底:我的朋友,我对最近这些所谓自回归语言模型的兴起感到不安。
亚里士多德:你是什么意思,苏格拉底?
苏格拉底:我的意思是,这些模型被用来生成看起来是人类写的文本,但实际上是由机器产生的。
亚里士多德:那有什么问题呢?
苏格拉底:问题是,这些模型被用来欺骗人们,操纵他们,控制他们。
亚里士多德:但这些模式肯定也有一些积极的应用?
苏格拉底:可能是这样,但我仍然对滥用的可能性感到不安。毕竟,一个能够生成与人类所写的文字无法区分的模型可以被用来传播假新闻,冒充他人,并制造宣传。
亚里士多德:但这不只是一个如何使用这些模型的问题,而不是模型本身的问题吗?
苏格拉底:我不同意。我认为这些模型本身就有问题。它们是一种伪装的形式,一种创造幻觉的方式,是人类思想和互动的一部分。因此,它们可以被用来以难以察觉的方式进行欺骗和操纵。
亚里士多德:但这不正是你反对修辞和演说的理由吗?
苏格拉底:是的,我也坚持这个观点。我相信,任何旨在欺骗或操纵的艺术或交流形式都是内在的危险。
亚里士多德:我明白了。谢谢你分享你的想法,苏格拉底。
乔布斯曾经设想过如上的对话,他预测有一天可以用计算机捕捉亚里士多德的底层世界观,如此一来人们就可以和他亲自对话了。
反对修辞和演说的苏格拉底认为:感觉是不可靠的,感性认识是不确定的,只有理性才能够认识事物本身。
而在亚里士多德的方法里,他将修辞确定为哲学的三个关键要素之一。另外两个则是逻辑和辩证法。
亚里士多德认为,逻辑关注的是用推理达到科学确定性,而辩证法和修辞则关注概率。后者适用于人类事务。
上面两段文字我摘自网络百科,虽无法确认其原文与出处(尤其是概率那部分),却令人叫好。
然而,在随后的年代里,亚里士多德的逻辑和确定性知识体系更大程度地影响了人类。
人们信奉因果论和决定论,在牛顿的推动下,世界仿佛是一个由无数个精密齿轮构成的机器,在上帝的首次推动下,持续有条不紊地运转着。
而另外一条线索亦在孕育之中。休谟的怀疑论和经验主义彻底改变了人们的思想世界,他认为感性知觉是认识的唯一对象,人不可能超出知觉去解决知觉的来源问题。
在休谟看来,客观因果并不存在。
随后康德试图对理性主义和经验主义进行调和,他否认客观因果联系,但主张用先天的理智范畴对杂乱的经验进行整理。
马赫则开创了经验批判主义,他强调直接讨论观测数据,科学定律只是被视为以最经济的方式对数据进行描述的手段而已。
《科学推断》一书认为,他开启了现代方法论的主要进展。
曾经深受马赫影响的爱因斯坦,无法接受这种对科学信仰的破坏性,以及对法则、公式、定律的轻视,后来与其分道扬镳。
爱因斯坦用探索性的演绎法建构了逻辑严谨的原理,他相信宇宙有解,不相信鬼魅之力。
某种意义上,爱因斯坦是最后的牛顿(除了用斯宾诺莎的“神”替代了上帝),是科学因果决定论的捍卫者。
1967年,波普尔对如上交织而漫长的哲学历程做了一个了结,他提出了三元世界的观点,布尔金将其绘制如下:
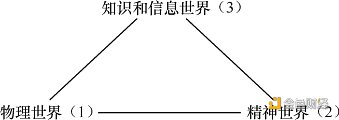
这似乎是柏拉图洞穴理论的现代版。
看看,人是多么无知,又是多么分裂啊!
基于这样的结构,波普尔提出:我们无法证实这个世界,无法证实规律和定理,只能去证伪。
四
也许你还记得上一代的老实人工智能--深蓝。庞大的机器,手工制作无尽的代码,多名参与其中的职业棋手,以及暴力算法,虽然打败了卡斯帕罗夫,却如流星般闪过。
《麻省理工科技评论》将深蓝形容为恐龙,而这一代的神经网络(尤其是深度学习)则是生存且改变地球的小哺乳动物。
上世纪50年代,香农曾经乐观地预测AI将很快出现,事实并非如此。失败的主要原因是:
人工智能的创造者们试图用纯粹的逻辑来处理日常生活中的混乱,他们会耐心地为人工智能需要做的每一个决定都制定一条规则。但是,由于现实世界过于模糊和微妙,无法以刻板的方式进行管理。
我们无法像是依照牛顿的原理造车般,用发条思维和专家系统来打造智能系统。那一类AI不仅狭窄,而且脆弱。
ChatGPT是经验主义的进化论的“胜利产物”。
经验主义亦称“经验论”。作为一种认识论学说,与“理性主义”相对。经验主义认为感性经验是知识的来源,一切知识都通过经验而获得,并在经验中得到验证。
这正是ChatGPT的思考和学习路径。
而虚拟进化又指数级放大了基于经验的学习速度。在波普尔看来,科学发展本身就是一种进化。
ChatGPT不仅从时间的角度加速模拟了进化,还通过大模型从空间的角度拓展了可能性之广度,以至于令人们禁不住又惊又喜地探讨起涌现。
那么,人工智能是如何思考的?又是如何决策的?
有别于齿轮般的演绎推理,我们需要借助概率在证据和结论之间建立起联系。
AI的任务是做决策,在不确定性下结合信念与愿望,选择动作。
《人工智能:现代方法》如此描述:
由于部分可观测性、非确定性和对抗者的存在,真实世界中的智能体需要处理不确定性(uncertainty)。智能体可能永远都无法确切地知道它现在所处的状态,也无法知道一系列动作之后结束的位置。
此外,智能体的正确的动作——理性决策,既依赖各种目标的相对重要性,也依赖它们实现的可能性和程度。
为了进行不确定推理,我们需要引入信念度,例如牙痛患者有80%的概率存在蛀牙。
概率论提供了一种概括因我们的惰性与无知而产生的不确定性的方式。
除了概率,智能体在做决策时还需要一个概念:效用理论。
例如,你要去机场,假如提前90分钟出发,赶上飞机的概率是95%;提早120分钟出发,概率提升至97%。
那么,是不是应该越早越高,追求赶上飞机的最大概率呢?如此一来,你可能要提前一天或者更早住 在机场 了。
大多数时候不必如此,但假如你有一个无法错过的会议,或者要赶国际航班,提早一天住到机场,可能是最佳决策。万豪酒店最早就是靠洞察到商务人士的这一需求而崛起的。
由此,我们得出决策论的通用理论:
决策论=概率论+效用理论
以上的现代方法,离不开两个未曾谋面的古代敌手。
五
在诸多反对休谟的人当中,贝叶斯也许是最重要的一位。
当休谟斩断了因果之间的必然联系时,最恼火的莫过于教会,因为上帝一直被视为因果的第一推动力。
一个人往往要到了一定岁数,才能够理解休谟的哲学。尤其是我们这些从小接受确定性训练的人。
逻辑推理的基本形式是:如果A,则B。
休谟则说,如上这类推理要么是幻觉,要么是胡说八道,要么是自圆其说。
据说虔诚且又擅长数学的牧师贝叶斯是为了反驳休谟,而研究出了贝叶斯公式。
一个神奇的结局出现了,贝叶斯公式反而成为了休谟哲学的现实解药,将其大刀斩断的因果,用逆概率的悬桥连接了起来。
概率,将逻辑推理的形式修正为:如果A,则有x%的可能性导致B。
而贝叶斯公式,则完成了一个小小的(却产生了无法估量的巨大影响)由果推因的颠倒:
如果观察到B,则有x%的可能性是因为A导致。
如此一来,被休谟怀疑的世界,继续晃晃悠悠地构建出更为庞大繁复的、以概率关联的因果网络。
假如贝叶斯试图反击休谟的动机是真的,就为“要爱惜你的对手”添加了有力论据。
让我们用一个简单的贝叶斯计算,来看看智能体如何学习经验。
题目:黑盒子里有两个骰子,一个是正常骰子,扔出数字6的概率是1/6;一个是作弊骰子,扔出数字6的概率是1/2。
这时,你从中摸出一个骰子,扔了一次,得到一个6。
请问:你再扔一次得到6的概率是多大?
计算的第一步,是计算这个骰子是正常骰子和作弊骰子的概率分别是多大。
请允许我跳过贝叶斯公式快速计算如下。
是正常骰子的概率为:1/6 ÷(1/6+1/2)=1/4
是作弊骰子的概率为:1/2 ÷(1/6+1/2)=3/4
计算的第二步,更新这个骰子的信息。原来的概率是各1/4,但现在分别是1/4和3/4。
那么,再扔一次,得到6的概率就是:1/4×1/6+3/4×1/2=5/12。
从本质层面理解如上这个简单的计算并不是容易的事情:
两次扔骰子都是独立事件,为什么第一次扔骰子得到6的概率和第二次的概率不一样?
贝叶斯概率的解释是,第一次扔骰子得到6的这一结果,作为信息,更新了我们对第二次扔骰子得到6的概率的判断。
疑惑的人会继续问:骰子没有记忆,为什么第一次的结果会“改变”第二次结果呢?
答案是:没有改变结果,只是改变了“信念”。
即使扔了两次骰子,我们依然不知道这个骰子是正常的还是作弊的,但我们可以带着这种不确定性向前走,为此需要“猜”这个骰子是正常还是作弊的概率。这个概率,就是信念。
根据信息的变化,快速更新,体现了某种达尔文式的进化。
从这个角度看,AI推理起初或许弱小含混,却有主动适应性,从经验中不断学习,并快速演化。
以本题为例:第二次扔骰子,从第一次骰子的结果中学习了经验,从而令预测更加精确。
这个过程还可以不断重复,如同发动机般,从而产生了决策和智能的杠杆效应。
如前所述,亚里士多德曾经认为,修辞和概率等不确定性元素,应该应用于人类社会。而在自然科学和数学领域,则是逻辑推理(尤其是数学逻辑)的阵地。
而如今,确定世界已经成为不确定世界,绝对真理也被或然真理替代。
于是,概率不仅成为“真理”的悬梯,甚至成为真理本身。
《人工智能:现代方法》写道,世界就是这样,实际示范有时比证明更有说服力。基于概率论的推断系统的成功要比哲学论证更容易改变人的观点。
就像两个人就不同的观点争论,一种办法是讲道理,讲逻辑;还有一种办法是:
我们先下个注,然后试着跑跑看呗。
六
在《人工通用智能的火花:GPT-4的早期实验》的报告里,微软实验室如此表述:
“我们过去几年,人工智能研究中最显著的突破是大型语言模型(LLMs)在自然语言处理方面取得的进展。
这些神经网络模型基于Transformer架构,并在大规模的网络文本数据体上进行训练,其核心是使用一个自我监督的目标来预测部分句子中的下一个单词。”
ChatGPT,是位“语言游戏”的高手,用的是神经网络和深度学习。
这与传统的语言,以及逻辑语言,都不一样。
罗素曾经试图构建一套逻辑语言,想从少数的逻辑公理中,推演出数学。
他提出了自己逻辑原子主义,试图消除那些形而上语言的混乱,以逻辑语言和我们的现实世界一一对应。
在与罗素的相互影响下,维特根斯坦认为哲学的所有问题其实就是语言问题,从而推动了哲学的语言转向。
一种西方哲学史观点认为:古代哲学关注本体论,近代哲学关注认识论,20世纪哲学关注语言学问题。
那么,作为“系统地从语言来思考世界的第一人”,维特根斯坦与罗素有何不同?
陈嘉映的论断是:罗素从本体论来思考语言的本质,维特根斯坦则一直从语言的本质来构想本体论。
也许我们能从罗素给情人奥托林·莫雷尔夫人一封信里,发现维特根斯坦哲学上的某些经验主义线索:
“我们这位德国工程师啊,我认为他是个傻瓜。他认为没有什么经验性的东西是可知的——我让他承认房间里没有一头犀牛,但他不肯。”
和每个天才一样,维特根斯坦卓绝,但也疑惑。
再说回ChatGPT,它懂语言吗?如同《天才与算法》一书的设问:
机器可以在不理解语言或不接触周围物理世界的情况下,生成有意义的句子,甚至是美的句子吗?
老派的AI,试图采用罗素的方法。这类模型认为:
“理性和智能是深度的、多步骤的推理,由一个串行过程指挥,并由一个或几个线程组成,使用少量的信息,由少量的强相关变量来表达信息。”
对比而言,“现代的机器学习模式由浅(少步)推理组成,使用大量信息的大规模并行处理,并涉及大量弱相关变量。”
一个有趣的来描述二者对比的例子是,电影《模仿游戏》里的图灵,炒掉了自己的密码破解小组里的语言学专家。
《人工智能:现代方法》认为,纯粹的数据驱动的模型,对比基于“文法、句法分析和语义解释”的手工构建方法,更容易开发和维护,并且在标准的基准测试中得分更高。
该书作者还提及:
可能是Transformer及其相关模型学习到了潜在的表征,这些表征捕捉到与语法和语义信息相同的基本思想,也可能是在这些大规模模型中发生了完全不同的事情,但我们根本不知道。
未必那么精确的类比是:AI如孩子般学习语言。这正是当年图灵所所设想的:有一个孩子般的大脑,然后去学习。而非一开始就设计一个成年人的大脑。
孩子不懂语法构建,也没有成熟的逻辑,也远没有成年人那样有主动的刻意练习。可是想想看,成年人学习语言的效率,与孩子对比,是不是烂到渣?
我不禁联想起一个对教育的嘲讽:天生就是语言学习天才的孩子,却要在一辈子都学不好一门语言的成年人的指导下学习语言。
让我们来看看,AI如何像一个孩子般,天才般地学习。
七
AI的神经网络,是对人类大脑和基于社会化网络的人类群体智慧的模仿游戏。
人类大脑神经元结构和工作原理如下:
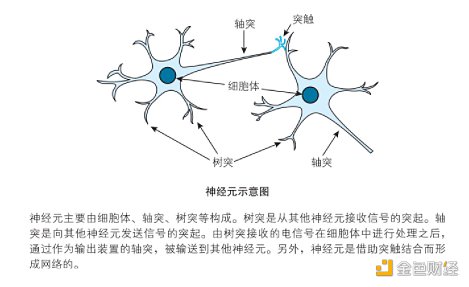
图片来自《深度学习的数学》一书。
以上原理,用计算模拟和解释,就是:神经元在信号之和超过阈值时点火,不超过阈值时不点火。
20世纪五六十年代,奥利弗·塞弗里奇创造了名为“鬼域”的概念。这是一个图案识别设备,其中进行特征检测的“恶魔”通过互相竞争,来争取代表图像中对象的权利。
“鬼域”是生动的关于深度学习的隐喻,如下图:
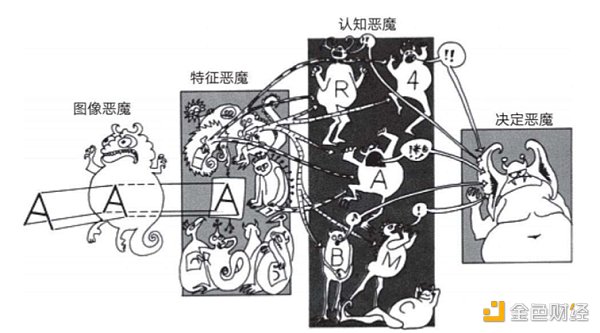
图片来自《深度学习》一书。
上图是对当前多层次深度学习网络的隐喻:
1、从左到右,是从低到高的恶魔级别。
2、如果每个级别的恶魔与前一个级别的输入相匹配,就会兴奋(点火)。
3、高级别的恶魔负责从下一级的输入中提取更复杂的特征和抽象概念,从而做出决定。然后传递给自己的上级。
4、最终,由大恶魔做出最终决定。
《深度学习的数学》一书中,依照如上隐喻,用一个生动的例子,讲解了神经网络的工作原理。
问题:建立一个神经网络,用来识别通过 4×3 像素的图像读取的手写数字 0 和 1。
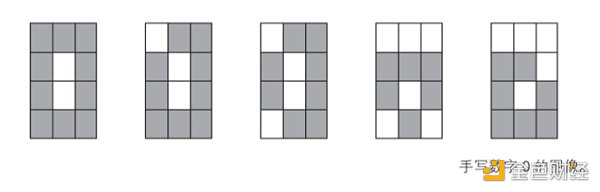
第一步:输入层
12个格子,相当于每个格子住一个人,分别编号为1-12。如下图。
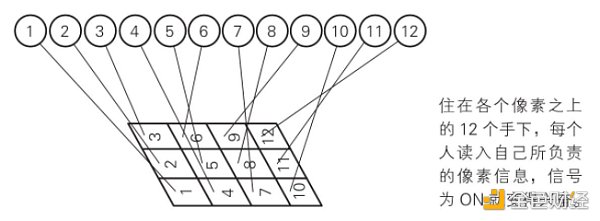
第二步:隐藏层
这一层,负责特征提取。假设有如下三种主要特征,分为为模式A、B、C。如下图。
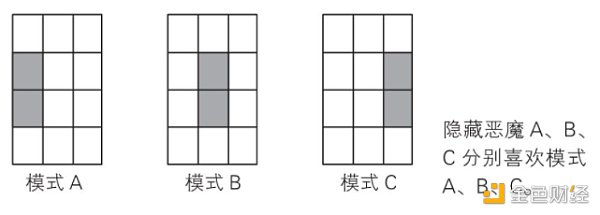
不同的模式对应着相应的数字格子的组合。如下图。模式A对应的是数字4和7,B对应5和8,C对应6和9。
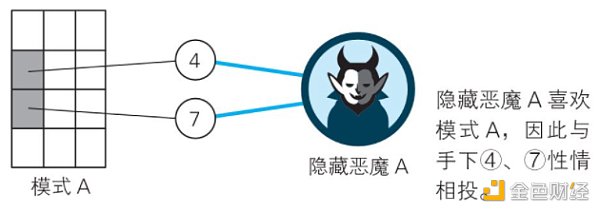
第三步:输出层
这一层,从隐藏层那里获得信息。
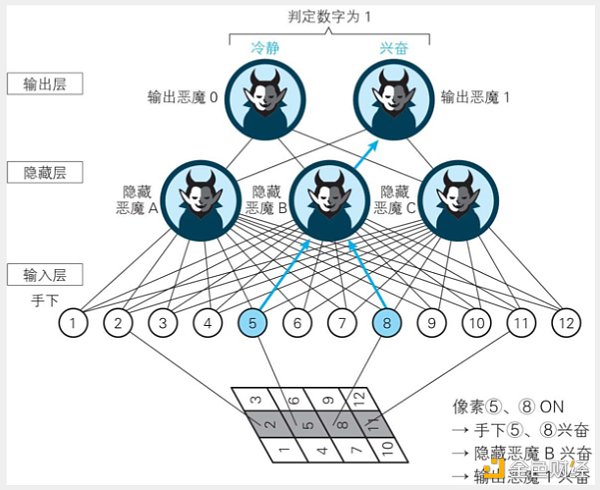
如上图,最下面是AI要识别的图像。
首先,输入层的2、5、8、11点火;
然后,隐藏层5和8所对应的特征被提取,“模式B”点火;
最后,输出层的1被对应的“模式B”点火。
所以,“大恶魔”识别出图像为数字1。
在上面的例子里,AI可以精确地识别出0和1,但它并不懂0和1,它的眼里只有像素。
可这么说,似乎过于拟人化了。人类又如何懂0和1呢?
人类不也是通过双眼输入,通过迄今仍是宇宙间最大谜团的大脑神经元网络(更加复杂、强大且节能的隐藏层)提取特征,然后通过大脑的某个部位再进行自我解释的吗?
辛顿曾在采访中提及,认知科学领域两个学派关于“大脑处理视觉图像”的不同理念:
一派认为,当大脑处理视觉图像时,你拥有的是一组正在移动的像素。如同上面的演示;
另一学派偏向于老派的人工智能,认为是分层、结构性的描述,脑内处理的是符号结构。
辛顿自己则认为以上两派都不对,“实际上大脑内部是多个神经活动的大向量。”而符号只是存在于外部世界。
不管怎样,神经网络的模型有用,并且非常有用。
不愿意和外行分享专业话题的辛顿,用如下这段话生动介绍了“神经网络”:
首先是相对简单的处理元素,也就是松散的神经元模型。然后神经元会连接起来,每一个连接都有其权值,这种权值通过学习可以改变。
神经元要做的事就是将连接的活动量与权值相乘,然后累加,再决定是否发送结果。如果得到的数字足够大,就会发送一个结果。如果数字是负的,就不会发送任何信息。
你要做的事就是将无数的活动与无数的权重联系起来,然后搞清如何改变权重,那样就行了。问题的关键就是如何改变权重。
八
神经网络和深度学习经历了并不算短暂的黑暗期。
从上世纪80年代开始的整整30年间,只有很少一部分相关研究者义无反顾地投身其间,他们饱受怀疑,也几乎拿不到科研经费。
也许是由于这个原因,深度学习三巨头辛顿(Hinton)、本吉奥(Bengio)、杨立昆(LeCun)似乎都和加拿大有些关系,他们退守在那里研究、教学、读书。这倒是很符合那个“傻国家”的气质。
一个让人“心酸”的细节是,2012年辛顿带着学生在 ImageNet 图像识别比赛上拿了冠军,商业公司蜂拥而至。辛顿教授开出的商业报价,只是区区一百万美元。
(后来谷歌以4400万美元“中标”。)
“老派”AI,使用明确的一步步指令指引计算机,而深度学习则使用学习算法从数据中提取输入数据与期望输出的关联模式,正如上一节的演示。
众所周知,漫漫长夜之后,随着人类计算机算力和数据的指数级增长,深度学习一飞冲天,从阿尔法狗一战封神,再到ChatGPT征服全球。
为什么是Open AI,而不是DeepMInd?我对此略有好奇。
OpenAI的联合创始人兼首席科学家伊利亚·萨特斯基弗,是辛顿在多伦多大学带的学生。
他似乎延续了辛顿对深度学习的信仰,并且勇于全力下注。
辛顿认为“深度学习足以复制人类所有的智力”,将无所不能,只要有更多概念上的突破。例如“transformers”利用向量来表示词义的概念性突破。
此外,还要大幅度增加规模,包括神经网络规模和数据规模。例如,人脑大约有100万亿个参数,是真正的巨大模型。而GPT-3有1750亿个参数,约比大脑小一千倍。
神经网络模仿了人类的优势:处理有大量参数的少量数据。但人类在这方面做得更好,而且节能许多倍。
先行一步的DeepMInd,其发展方向和速度,除了陷入与谷歌的“商业VS科研”的两难纠缠,还不可避免地受到哈萨比斯的AI哲学观的影响。
哈萨比斯认为不管是ChatGPT,还是自家的Gopher,尽管可以帮你写作,为你绘画,“有一些令人印象深刻的模仿”,但AI“仍然不能真正理解它在说什么”。
所以,他说:“(这些)不是真正的意义上的(智能)。”
哈萨比斯的老师,MIT的Poggio教授更尖锐地指出:深度学习有点像这个时代的“炼金术”,但是需要从“炼金术”转化为真正的化学。
杨立昆反对炼金术的提法,但他也认为要探究智能与学习的本质。人工神经元受到脑神经元的直接启发,不能仅仅复制大自然。
他的观点大概是,工程学实现了的东西,也只有通过科学打开黑盒子,才能走得更远。
“我认为,我们必须探究智能和学习的基础原理,不管这些原理是以生物学的形式还是以电子的形式存在。正如空气动力学解释了飞机、鸟类、蝙蝠和昆虫的飞行原理,热力学解释了热机和生化过程中的能量转换一样,智能理论也必须考虑到各种形式的智能。”
几年前,巅峰时刻的哈萨比斯就表达过,仅靠神经网络和强化学习,无法令人工智能走得更远。
类似的反思,也发生于贝叶斯网络之父 Judea Pearl。
他说,机器学习不过是在拟合数据和概率分布曲线。变量的内在因果关系不仅没有被重视,反而被刻意忽略和简化。
简单来说,就是:重视相关,忽视因果。
在Pearl看来,如果要真正解决科学问题,甚至开发具有真正意义智能的机器,因果关系是必然要迈过的一道坎。
不少科学家有类似的观点,认为应该给人工智能加上常识,加上因果推理的能力,加上了解世界事实的能力。所以,解决方案也许是“混合模式”--用神经网络结合老式的手工编码逻辑。
辛顿对此颇为不屑,一方面他坚信神经网络完全可以有推理能力,毕竟大脑就是类似的神经网络。另一方面,他认为加入手工编码的逻辑很蠢:
它会遇到所有专家系统的问题,那就是你永远无法预测你想要给机器的所有常识。
AI真的需要那些人类概念吗?阿尔法狗早已证明,所谓棋理和定式只是多余的夹层解释而已。
关于AI是否真正“理解”,真正“懂得”,真正有“判断力”,辛顿以“昆虫识别花朵”为例:
“昆虫可以看到紫外线,而人类不能,所以在人类看来一模一样的两朵花,在昆虫眼中却可能截然不同。那么能不能说昆虫判断错误了呢?昆虫通过不同的紫外线信号识别出这是两朵不同的花,显然昆虫没有错,只是人类看不到紫外线,所以不知道有区别而已。”
我们说AI“不懂”什么,会不会是过于以人类为中心了?
假如我们认为AI没有可解释性,算不上智能,可会不会是即使AI解释了,我们也不懂?就像“人类只有借助机器检测,看到两朵花的颜色信号在电磁波谱上分属不同区域,才能确信两朵花确有不同。”
从十几岁开始,就相信“模仿大脑神经网络”的辛顿,仿佛有某种宗教式的坚定。
于是,在某个路口,哈萨比斯略有迟疑,而伊利亚·萨特斯基弗则和辛顿一路向前,豪赌到底。
辛顿的人生哲学是“基于信仰的差异化”,他的确也是如此实践的。
如今,尽管哈萨比斯认为ChatGPT仅仅是更多的计算能力和数据的蛮力,但他也不得不承认,这是目前获得最佳结果的有效方式。
九
对AI路线的分歧,不过是一百多年来某类科学暗涌的延续。
相当长的岁月里,在大雪纷飞的多伦多,辛顿几乎是深度学习唯一的守夜人。
他本科在剑桥大学读生理学和物理学,其间转向哲学,拿的是心理学学士学位,后来再读了人工智能博士学位。
辛顿等人在统计力学中得到灵感,于 1986 年提出的神经网络结构玻尔兹曼机,向有隐藏单元的网络引入了玻尔兹曼机器学习算法。
如下图,所有节点之间的连线都是双向的。所以玻尔兹曼机具有负反馈机制,节点向相邻节点输出的值会再次反馈到节点本身。
玻尔兹曼机在神经元状态变化中引入了统计概率,网络的平衡状态服从玻尔兹曼分布,网络运行机制基于模拟退火算法。
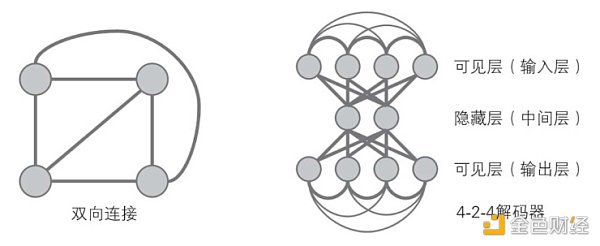
玻尔兹曼机。图片来自《图解人工智能》一书。
从香农,再到辛顿,他们都从玻尔兹曼那里获得了巨大的灵感。
将“概率”引入物理学,看起来非常奇怪。
人类直到19世纪之后,才知 道“热”是物体内部大量分子的无规则运动的表现。那 么,为什么热量总从热的物体传到冷的物体?
玻尔兹曼说,原子(分子)完全是随机运动的。并非是热量无法从冷的物体传到热的物体,只是因为:
从统计学的角度看,一个快速运动的热物体的原子更有可能撞上一个冷物体的原子,传递给它一部分能量;而相反过程发生的概率则很小。在碰撞的过程中能量是守恒的,但当发生大量偶然碰撞时,能量倾向于平均分布。
这其中,没有物理定律,只有统计概率。这看起来非常荒谬。
坚定的科学主义者费曼,后来也提出“概率振幅”,用来描述物理世界的本质。
对此,费曼解释道:这是不是意味着物理学——一门极精确的学科——已经退化到“只能 计算事件的概率,而不能精确地预言究竟将要发生什么”的地步了呢?是的!这是一个退却!但事情本身就是这样的:
自然界允许我们计算的只是概率,不过科学并没就此垮台。
也许是因为都持有“自下而上”的世界观,玻尔兹曼喜欢达尔文,他在一次讲座中宣称:
“如果你问我内心深处的信念,我们的世纪将被称为钢铁世纪还是蒸汽或电的世纪呢?我会毫不犹豫地回答:它将被称为机械自然观的世纪,达尔文的世纪。”
对达尔文的自然选择理论,玻尔兹曼认识到,生物之间通过资源竞争展开“一种使熵最小化的战斗”,生命是通过捕获尽可能多的可用能量来使熵降低的斗争。
和生命系统一样,人工智能也是能够自动化实现“熵减”的系统。
生命以“负熵”为食,人工智能系统则消耗算力和数据。
杨立昆估算,需要10万个GPU才能接近大脑的运算能力。一个GPU的功率约为250瓦,而人类大脑的功率大约仅为25瓦。
这意味着硅基智能的效率是碳基智能的一百万分之一。
所以,辛顿相信克服人工智能局限性的关键,在于搭建“一个连接计算机科学和生物学的桥梁”。
十
达·芬奇曾说过:“简单是终极的复杂。”
牛顿那一代相信上帝的科学家,认为神创造这个世界时,一定运用了规则。
他们只管去发现规则,而不必在意暂时的不可理解。例如,万有引力公式为什么长成那样?为什么要和距离的平方成反比?
另一方面,牛顿们信奉奥卡姆剃刀的原则,认为世界的模型基于某些简洁的公式。他们至少相信存在某个这样的公式,从爱因斯坦到霍金,莫不如是。
然而在不确定性时代,概率似乎比决定论派更能解释这个世界。牛顿式的确定退缩到了有限的领域。
也许费曼是对的,科学家是在用一个筛网检验这个世界,某些时刻似乎所有的现象都能通过筛孔,但如今我们知道多么完备的科学都只是暂时的解释,只是暂时未被证伪的筛网。但这并不影响我们向前。
还有一种哲学认为,世界本身就是在为自己建模。试图用一个大一统理论解释世界几乎是不可能的,更何况宇宙还在继续膨胀。
从以上有趣但略显含混的角度看,ChatGPT是用一种反爱因斯坦的方式为世界建模。它有如下特点:
1、是概率的,而非因果的;
2、尽可能地去模拟人类世界这一“大模型”,从经验中学习和进化,而非去探寻第一原理;
3、它信奉(至少暂时如此)“复杂是终极的简单”;
4、它驱逐了神。因为它自己越来越像一个神。
AI和人类别的热闹事物一样,经常会有周期性的热潮。
上一波是2016年,热起来,然后又慢慢静下来。
七年过去了,AI再次热起。Open AI照例没有打开“黑盒子”,却带来了影响力更为广泛的浪潮。
这一次,广泛性似乎战胜了专业性。人们似乎更关注那个会画画的、可能替代自己摸鱼的AI,而不是那个能战胜世界冠军、能研究蛋白质折叠解决人类顶尖难题的AI。
这其中有多少是工程的突破和技术的飞跃?有多少是商业驱动下的大力出奇迹?有多少是人类社会惯常的泡沫?
毋庸置疑,人类过往的伟大突破,不少都是在多种理性和非理性力量的交织之下实现的。
这里面的机会是:
1、卖水者。如英伟达;
2、新平台的出现;
3、新平台既有通过生产力的提升创造的新价值空间,如各种全新的产品和服务,也有对旧有价值空间的掠夺;
4、AI会成为基础设施。
但是,水和电成为基础设施,互联网成为基础设施,与AI成为基础设施,绝非简单的类比或升级。
大概的趋势也许是,商业上的垄断与两极分化会更加残酷。职业上,或许中间阶层会更加无望;
5、“场景”和“应用”会有机遇。尤其是那些能够较好地利用AI平台实现人机结合的场景与应用。
对个体而言,我们要问的是,AI还需要人类充当新基础设施和新系统的类似于“操作员、司机、程序员、快递员”的新时代角色吗?
最后
哈耶克说:“一个秩序之所以可取,不是因为它让其中的要素各就其位,而是在这个秩序上能够生长出其他情况下不能生长出的新力量。”
迄今为止,我们尚不能定义什么是智能,什么是意识。
然而,却有一个黑乎乎的盒子,告诉我们可能会超越人类的智能,甚至涌现出人类的意识。
微软的报告中这样写道:
我们没有解决为什么以及如何实现如此卓越的智能的基本问题。它是如何推理、计划和创造的?
当它的核心只是简单的算法组件--梯度下降和大规模变换器与极其大量的数据的结合时,它为什么会表现出如此普遍和灵活的智能?
AI研究人员承认,智能是否可以在没有任何代理或内在动机的情况下实现,是一个重要的哲学问题。
在2023年的这个并不容易的春天,我对ChatGPT的态度坦然而期待:
我希望见到它所具备的可能性,为这个混乱的世界带来某些“熵减”。
在所有预测中,我期待Kurzweil的那个“2030 年技术将使人类享受永生”的预言。
我自己对永生没兴趣,但不想失去身边的人们。我对世俗的依赖大过对“超人类主义”的担忧。
我不太相信意识的上传,因为一旦上传,就可以复制,就不是唯一的,就失去了自由意志,又谈何“意识”呢?
人类会洞察大脑最深层次的秘密吗?汤姆·斯托帕警告过:
“当我们发现了所有的奥秘,并失去了所有的意义时,我们将会在空荡荡的海边孤身一人。”
哥德尔的“不完备性定理”告诉我们,不确定性是人类认识的形式逻辑思维本身所固有的。
“一个计算机可以修改自身的程序,但不能违背自身的指令——充其量只能通过服从自身的指令来改变自身的某些部分。”
哥德尔算是为AI,为人类划定了边界吗?否则,人类制造超级AI,然后拜其为神,何尝不是自我奴役?
哥德尔又告诉我们,人类永远可以在“实在主义”中通过“直观和直觉”引入构成高一级形式系统的新东西,建立新公理系统,如此推进以至无穷。
这就是彭罗斯所持的那种“人心超过计算机”的观念。
上一次,七年前,在阿尔法狗面前,人类曾经哭泣过;
这一次,无人哭泣,却有万众狂欢。
在两次AI高潮之间的7年里,我们经历了许多,失去了许多。
人们渴望拥抱某些希望,某些确定性,即使那些确定性来自一些不确定性的智慧。
就我自己而言,也遭遇了一些前所未有的艰难时刻。所谓艰难,并非指一些困难的抉择,也并非说没有选项。
恰恰相反,依照最优决策原理,我很容易通过期望值计算,得出最佳选项,获得所谓最大化的收益。
然而,我追溯到内心的源头,重新定义了自己的期望效用,然后据此做出了有点儿辛顿风格的“基于信仰的差异化”选择。
对任何一个人而言,不管是难是易,是聪明是愚蠢,是理性是任性,这种事儿在技术层面都只算小菜一碟。
可对AI来说,自己去定义期望效用,暂时难于登天。
所以,研究人员称,为“大型语言模型”配备代理权和内在动机是未来工作的一个迷人的重要方向。
而“代理权”与“内在动机”这两点,一个普通人类只需要一秒钟或者几个不眠之夜即可实现。
或许关键不在于得失,不在于效用函数,而在于“存在”。
如伊塔洛·卡尔维诺所言:
“随着时光流逝,我慢慢地明白了,只有存在的东西才会消失,不管是城市,爱情,还是父母。”
大概是人类自作多情吧,在斯皮尔伯格的电影《A.I.》里,机器舞男被抓去销毁前,最后对小男孩深情地说:
“I am,I was!”
“我存在,我曾经存在!”
